distribute
distribute is a relatively simple command line utility for distributing compute jobs across the powerful
lab computers. In essence, distribute provides a simple way to automatically schedule dozens of jobs
from different people across the small number of powerful computers in the lab.
Besides having the configuration files begin easier to use, distribute also contains a mechanism for
only scheduling your jobs on nodes that meet your criteria. If you require OpenFoam to run your simulation,
distribute automatically knows which of the three computers it can run the job on. This also allows you
to robustly choose what your requirements are for your tasks. This allows us to prioritize
use of the gpu machine to jobs requiring a gpu, increasing the overall throughput of jobs between all lab
members.
Another cool feature of distribute is that files that are not needed after each compute run are automatically
wiped from the hard drive, preserving limited disk space on the compute machines. Files that are specified to be
saved (by you) are archived automatically on a 24 TB storage machine, and can be retrieved (and filtered)
to your personal computer with a single short command.
distribute competes in the same space as slurm, which you would
likely find on an actual compute cluster. The benefit of distribute is an all-in-one solution to running,
archiving, and scheduling jobs with a single streamlined utility without messing around with the complexities
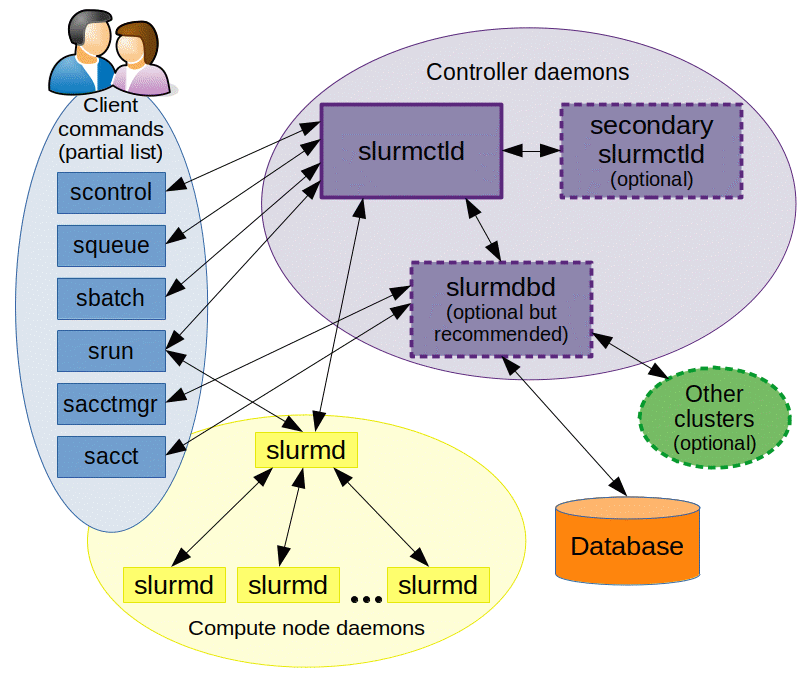
of the (very detailed) slurm documentation. If you are still unconvinced, take a look at the overall architecture
diagram that slurm provides:
Since the lab computers also function as day-to-day workstations for some lab members, some additional
features are required to ensure that they are functional outside of running jobs. distribute solves this issue
by allowing a user that is sitting at a computer to temporarily pause the currently executing job so that
they may perform some simple work. This allows lab members to still quickly iterate on ideas without waiting
hours for their jobs to reach the front of the queue. Since cluster computers are never used as
day-to-day workstations, popular compute schedulers like slurm don't provision for this.
Architecture
Instead of complex scheduling algorithms and job queues, we can distill the overall architecture of the system to a simple diagram:

In summary, there is a very simple flow of information from the server to the nodes, and from the nodes to the server. The server is charged with sending the nodes any user-specified files (such as initial conditions, solver input files, or csv's of information) as well as instructions on how to compile and run the project. Once the job has finished, the user's script will move any and all files that they wish to archive to a special directory. All files in the special directory will be transfered to the server and saved indefinitely.
The archiving structure of distribute helps free up disk space on your laptop of workstation, and instead
keep large files (that will surely be useful at a later date) stored away on a purpose-build machine to
hold them. As long as your are connected to the university network - VPN or otherwise - you can access the
files dumped by your compute job at any time.
Specifying Jobs
We have thus far talked about all the cool things we can do with distribute, but none of this is free. As
a famous Italian engineer once said, "Theres no such thing as free lunch." The largest complexity with working
with distribute is the configuration file that specifies how to compile run project. distribute template python
will generate the following file:
meta:
batch_name: your_jobset_name
namespace: example_namespace
matrix: ~
capabilities:
- gfortran
- python3
- apptainer
python:
initialize:
build_file: /path/to/build.py
jobs:
- name: job_1
file: execute_job.py
- name: job_2
file: execute_job_2.py
We will explain all of these fields later, but surmise it to say that the configuration files come in 3 main sections.
The meta section will describe things that the head node must do, including what "capabilities" each node is required
to have to run your server, a batch_name and namespace so that your compute results do not overwrite someone else's,
and a matrix field so that you can specify an optional matrix username that will be pinged once all your
jobs have finished.
The next section is the initialize section. This section specifies all the files and instructions that are required
to compile your project before it is run. This step is kept separate from the running step so that we can ensure
that your project is compiled only once before being run with different jobs in the third section.
The third section tells distribute how to execute each job. If you are using a python configuration then your
file parameter will likely seek out the compiled binary from the second step and run the binary using whatever
files you chose to be available.
The specifics of the configuration file will be discussed in greater detail in a later section.